Umsetzung des Projekt
Umsetzungsphasen
- Texterkennungscripte schreiben
Status: fertig, 15.07.2024 - Hoster finden, der MySQL-DB > GB und Fernzugriff erlaubt
Status: fertig, 19.07.2024 - Datenmodell und Datenstruktur schaffen
Status: fertig, 25.07.2024 - Datenimporter programmieren
Status: fertig, 21.07.2024 - Basis-Homepage mit Textsuche bauen
- Basisumsetzung (Adaption meiner privaten Homepage)
Status: fertig, 24.07.2024 - Cybersecurity-Aspekte programmieren
Status: fertig, 23.07.2024 - Suchfunktionen (nach Phrase, alle Begriffe, Profi mit RegExpr)
Status: fertig, 25.07.2024 - Bestandsübersicht
Status: fertig, 21.07.2024
- Basisumsetzung (Adaption meiner privaten Homepage)
- Testläufe mit einigen Nutzern, Akzeptanz prüfen
Status: lief anfangs mit etwas über 100 Seitenaufrufe pro Tag,
Tendenz rückläufig, da ich nicht dafür werbe. - Verbesserungen, Fehlerbeseitigungen
Status: in Arbeit - Bekanntmachung in Foren
(erst ab 15 Zeitungen mit allen verfügbaren Bänden)
Status: in Arbeit, am 07.01.2025 wurde eine Facebook-Seite dazu geschaffen. - Feature-Entwicklung
- Markierung von Personen, Orten, Ereignissen auf den Seiten
Status: fertig, 21.12.2024 - Suche nach Markierungen von Personen, Orten, Ereignissen
Status: fertig, 21.12.2024 - auf einer Karte bei den markierten Orten, die verknüpften Personen darstellen
Status: fertig, 11.08.2024 - Texteditor mit Rechtschreibprüfung
Status: am 09.01.2025 verworfen. Einige Browser bieten selbst eine Rechtschreibprüfung. Zudem erwies sich eine automatisierte Rechtschreibprüfung mit eigenem Wörterbuch mit typischen Texterkennungsfehlern bei Fraktur-Schrift gleich beim Import als effektiver. - Unschärfesuche mit Kölner Phonetik, ggf. Anpassung des Algorithmus hinsichtlich Fraktur-Texterkennungsfehler
Status: begonnen
- Markierung von Personen, Orten, Ereignissen auf den Seiten
Organisatorisch
Mein alter Webseitenhoster netbeat bot im derzeitigen Vertrag nur eine Datenbank mit 500 MB an und erlaubte keinen Remote-Zugang auf diese. So suchte ich nach einer Alternative und landete bei Netcup. Die Datenbank ist nur mit dem Speicherplatz von 75 GB beschränkt, remote-Zugang ist erlaubt, ich darf 3 Domain nutzen und bezahle ein Drittel weniger. Das ist ja mal ein netter Nebeneffekt.
Workflow
- Herunterladen der Dateien mittels Mouse-Makro-Recorder oder Skripten
- Sichtung, ggf. Entpacken von Zip-Dateien, Normierung der Dateinamen mit Total Commander
- via Bash-Shell-Skript wird geprüft, ob alle Dateien heruntergeladen wurden, ggf. Fehlende manuell heruntergeladen und umbenannt
- liegen die Datein als JPG-Datei oder JFIF-Datei vor, werden via Bash-Shell-Skript diese umgewandelt und eine Texterkennung durchgeführt und die erkannten Texte getrennt abgelegt
- liegen die Datein als PDF-Datei vor, werden via Bash-Shell-Skript die alten Texterkennung entfernt, eine neue Texterkennung durchgeführt, anschließend die Datei mittels Ghostskript verkleinert, und die erkannten Texte getrennt abgelegt
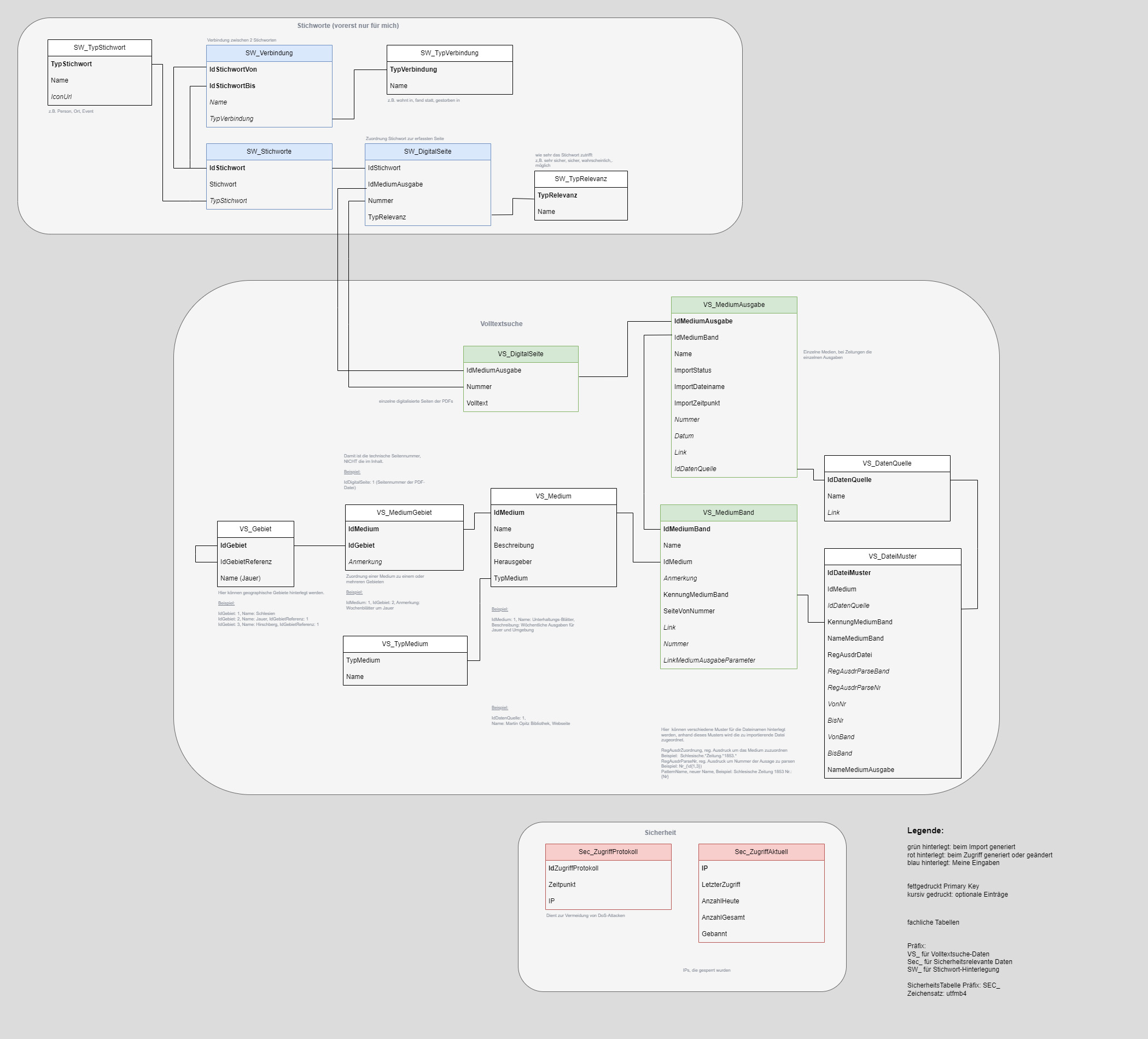
- ein PHP-Skript, durchsucht alle Ordner nach den Textdateien, prüft ob diese bereits importiert wurden. Wenn nicht wird der Dateiname der Textdatein mittels regulären Ausdrücken geprüft,
um welches Werk, Band und Ausgabe es sich handelt und diese in die Datenbank der Homepage geladen.
Datenmodell